2.1 Systematische Erfassung der Vorläuferfähigkeiten
Als Schule haben wir ein besonderes Interesse an den sogenannten „Vorläuferfähigkeiten“ der Kinder. Wir wollen also diese Kompetenzen der Kinder noch vor der Einschulung kennenlernen. Wenn wir die Kompetenzen der Kinder bereits vor der Einschulung kennen, dann können wir die individuelle Förderung passgenau im Voraus planen und auf eine möglichst leistungsheterogene Klassenzusammensetzung achten (sowohl leistungsstärkere als auch leistungsschwächere Kinder in einer Klasse).
Meine Schule kooperiert daher flächendeckend mit allen Kindertagestätten und Vorschulen in der Region. Noch vor dem Schuleintritt wird in der KiTa bzw. in der Vorschule ein Mathematik-Test durchgeführt. Wir haben uns für den Mathematik-Test „Mathes 0“ entschieden, ein Screening zur Erfassung der Mathematikleistungen zum Schulbeginn. Das besondere an diesem Mathematik-Test ist, dass die Entwicklung des Tests wissenschaftlich dokumentiert worden ist. Der Test wurde erprobt und die Ergebnisse und Erkenntnisse dieser Erprobung sind ebenfalls wissenschaftlich dokumentiert. Entwicklung und Qualität des Tests sind also weitestgehend transparent und nachvollziehbar dokumentiert. Das Testverfahren, Durchführungshinweise und die wissenschaftliche Dokumentation (Manual/Handbuch) sind frei verfügbar, aufgrund der sogenannten CC BY-NC-SA-Lizenz. Diese Lizenz erlaubt die kostenfreie Nutzung des Tests sowie die Weiterentwicklung des Tests. Das bedeutet, dass wir als Schule den Einsatz des Tests dokumentieren und den Test aufgrund unserer Erfahrung weiterentwickeln können. Wir haben z.B. festgestellt, dass der Test für einige Kinder zu schwer ist. Wir haben daher einige Aufgaben leichter gestaltet, um im niedrigen Leistungsspektrum besser differenzieren zu können. Den Prozess der Weiterentwicklung haben wir dokumentiert. Diese Dokumentation und die Weiterentwicklung des Tests haben wir ebenfalls mit CC BY-NC-SA-Lizenz veröffentlicht.
Damit schließt sich der Kreislauf von Open Science: Sowohl der Prozess der Weiterentwicklung als auch die Ergebnisse der Weiterentwicklung sind frei zugänglich und nutzbar. Andere Schulen und Forschende können von unseren Erkenntnissen profitieren, den weiterentwickelten Test einsetzen, den Test wiederum an ihre Bedürfnisse anpassen und die Erfahrungen ebenfalls dokumentieren und teilen. So entsteht ein kontinuierlicher Wissenskreislauf, bei dem wissenschaftliche Erkenntnisse transparent dokumentiert und frei zur Verfügung gestellt werden.
Mathes 0 - Screening zur Erfassung der Mathematikleistungen zum Schulbeginn
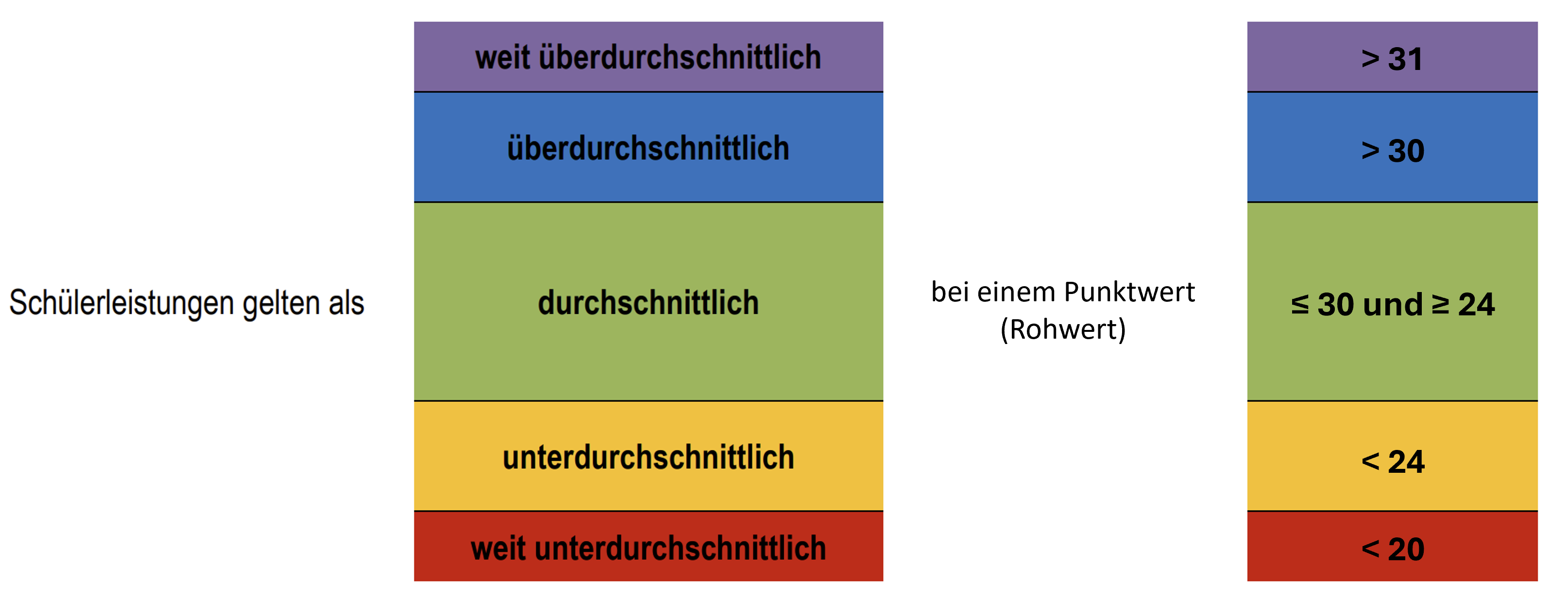
Der Mathematik-Test „Mathes-0“ wird in den KiTas und Vorschulen durchgeführt. Die bearbeiteten Tests werden an unsere Schule übersendet und wir beginnen mit der Auswertung der Tests. Die Auswertung erfolgt gemäß den Angaben in der Auswertungsvorlage. Die Werte der einzelnen Kinder können anschließend in eine dafür vorgesehene Excel-Tabelle übertragen werden. Gemäß den Angaben im Handbuch (hier und hier) erfolgt eine Kategorisierung in unterschiedliche Leistungsniveaus.
Referenzniveaus als Interpretationshilfen für die erzielte Testleistung gemäß den Angaben im Mathes-0-Handbuch (hier und hier)
Für das nächste Schuljahr wurden 87 Kinder an unserer Schule angemeldet (Einschulung). Wir haben daher einen Datensatz (Mathematik-Leistung) mit 87 Kindern. An unserer Schule analysieren wir diese Daten mit der frei verfügbaren Programmiersprache R. Die Programmiersprache R entspricht dem Gedanken der Offenen Wissenschaftspraxis, weil die Programmiersprache frei verfügbar ist und weil die Analyseschritte sehr transparent und nachvollziehbar dargestellt werden können (Analyse-Code der Programmiersprache R). Diese Analyseschritte können wiederum im Sinne der Offenen Wissenschaftspraxis öffentlich zugänglich gemacht werden. Die Analysen können dann von Außenstehenden (z.B. andere Schulen) sehr gut nachvollzogen, repliziert und sogar abgewandelt werden.
Nachfolgend sieht man den Analyse-Code der Programmiersprache R (“R-Code aufklappen”). Mit diesem Code (Analyse-Anweisungen) wird eine übersichtliche Tabelle mit den Leistungen aller Kinder erstellt (aus Datenschutzrechtlichen Gründen sind Pseudonyme anstatt von Klarnamen dargestellt).
R-Code aufklappen
library(gt) # gt Paket laden (https://gt.rstudio.com/)library(tidyverse) # gt tidyverse Paket laden (https://tidyverse.org/)# Tabellarische DarstellungDATEN %>%gt() %>%data_color(columns = Niveau,fn =function(x) {case_when( # Farbauswahl x =="weit überdurchschnittlich"~"#9B8BA8", # Purpur x =="überdurchschnittlich"~"#6B9AC4", # Blau x =="durchschnittlich"~"#A8C686", # Grün x =="unterdurchschnittlich"~"#E6B854", # Gelb x =="weit unterdurchschnittlich"~"#C85450"# Rot ) } ) %>%tab_header(title ="Testung vor Einschulung 2025/2026",subtitle ='Leistungen im Mathematik-Test "Mathes-0" in der KiTa bzw. Vorschule' )
Testung vor Einschulung 2025/2026
Leistungen im Mathematik-Test "Mathes-0" in der KiTa bzw. Vorschule
Pseudonym
Punkte (Rohwert)
Niveau
Christo
33
weit überdurchschnittlich
Karien
32
weit überdurchschnittlich
Andre
31
überdurchschnittlich
Annelise
31
überdurchschnittlich
Frans
31
überdurchschnittlich
Thandi
31
überdurchschnittlich
Elizma
30
durchschnittlich
Pule
30
durchschnittlich
Temba
30
durchschnittlich
Adriaan
30
durchschnittlich
Leah
30
durchschnittlich
Simone
29
durchschnittlich
Xolani
29
durchschnittlich
Tshepo
29
durchschnittlich
Petra
29
durchschnittlich
Zola
29
durchschnittlich
Ruan
29
durchschnittlich
Liezl
29
durchschnittlich
Elma
29
durchschnittlich
Lerato
29
durchschnittlich
Coenie
29
durchschnittlich
Zinhle
29
durchschnittlich
Pieter
29
durchschnittlich
Kgothatso
29
durchschnittlich
Mandla
29
durchschnittlich
Thabo
29
durchschnittlich
Retha
29
durchschnittlich
Nokuthula
28
durchschnittlich
Tessa
28
durchschnittlich
Hanno
28
durchschnittlich
Vuyani
28
durchschnittlich
Palesa
28
durchschnittlich
Kobus
28
durchschnittlich
Iman
28
durchschnittlich
Bonolo
27
durchschnittlich
Herman
27
durchschnittlich
Mia
27
durchschnittlich
Anika
27
durchschnittlich
Lukas
27
durchschnittlich
Mariska
27
durchschnittlich
Bongi
27
durchschnittlich
Hendrik
27
durchschnittlich
Jana
27
durchschnittlich
Gert
27
durchschnittlich
Dawid
27
durchschnittlich
Sizwe
27
durchschnittlich
Olivia
27
durchschnittlich
Nadine
27
durchschnittlich
Yolandi
27
durchschnittlich
Noah
26
durchschnittlich
Leonie
26
durchschnittlich
Ricky
26
durchschnittlich
Kea
26
durchschnittlich
Sara
26
durchschnittlich
Brendan
26
durchschnittlich
Mpho
26
durchschnittlich
Elsa
26
durchschnittlich
Sarel
26
durchschnittlich
Riana
26
durchschnittlich
Siphamandla
26
durchschnittlich
Heinrich
25
durchschnittlich
Rocco
25
durchschnittlich
Mandla
25
durchschnittlich
Nandi
25
durchschnittlich
Sibusiso
25
durchschnittlich
Ruan
25
durchschnittlich
Karla
25
durchschnittlich
Pieter
25
durchschnittlich
Vuyani
25
durchschnittlich
Refilwe
25
durchschnittlich
Diego
25
durchschnittlich
Palesa
24
durchschnittlich
Temba
24
durchschnittlich
Marthinus
24
durchschnittlich
Nosipho
24
durchschnittlich
Thandi
24
durchschnittlich
Sarel
24
durchschnittlich
Petra
24
durchschnittlich
Hendrik
24
durchschnittlich
Elsa
24
durchschnittlich
Christo
24
durchschnittlich
Karien
23
unterdurchschnittlich
Leah
23
unterdurchschnittlich
Tshepo
23
unterdurchschnittlich
Amahle
23
unterdurchschnittlich
Coenie
23
unterdurchschnittlich
Sipho
20
weit unterdurchschnittlich
2.3 Visualisierung der Daten
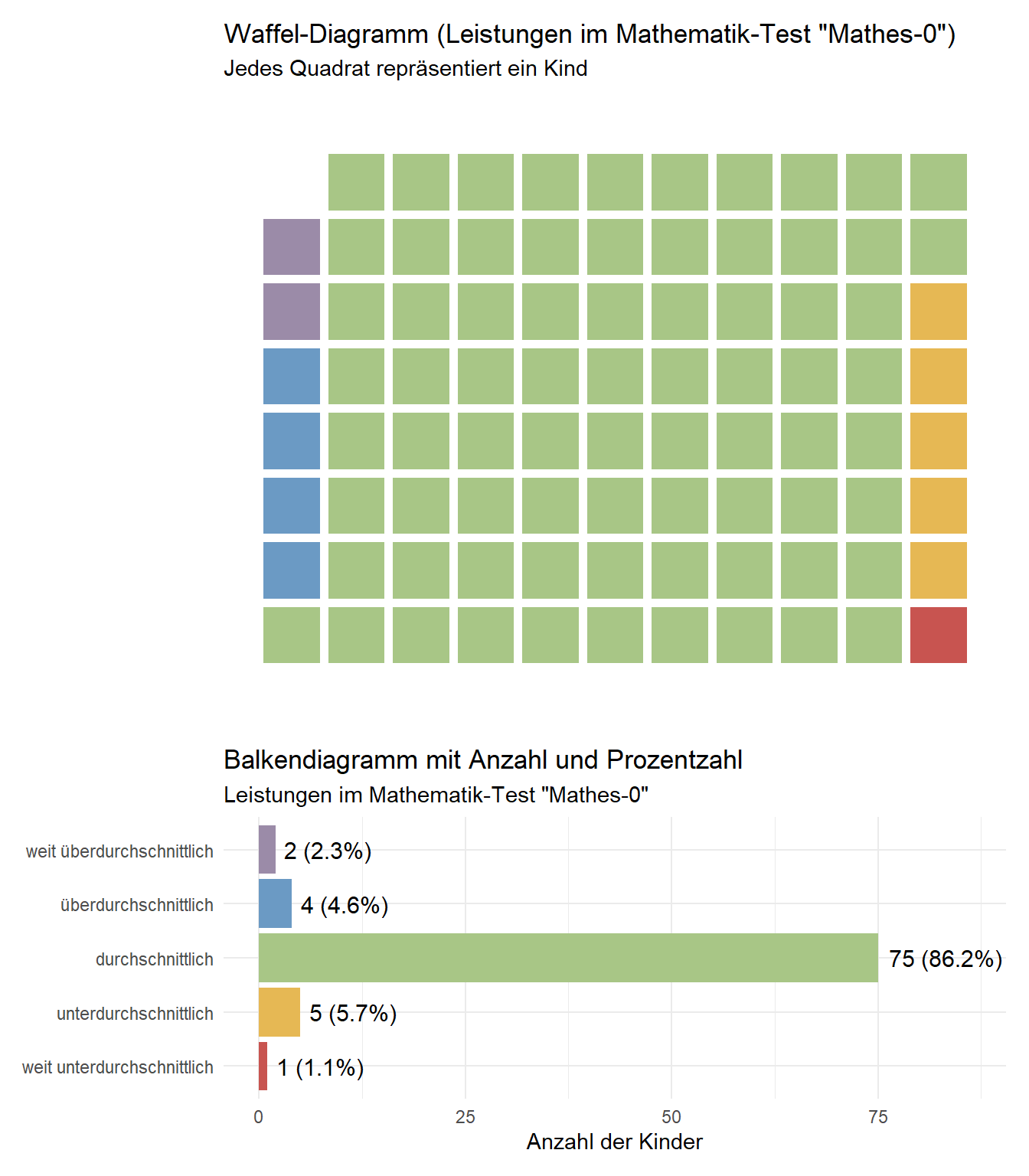
Bilder sagen bekanntlich mehr als Tabellen und tausend Worte. Wir entscheiden uns daher für eine grafische Darstellung der einzuschulenden Kinder. Mit dem Waffel-Diagramm wird jedes einzelne Kind als kleines Quadrat repräsentiert. Das dazugehörige Balkendiagramm zeigt uns die Anzahl und Prozentzahlen. Mit dieser Visualisierung verschaffen wir uns eine erste Übersicht über die Mathematik-Leistung der einzuschulenden Kinder.
Mit den vorausgegangenen Analysen und Visualisierungen haben wir uns eine Übersicht über die Mathematik-Leistung der einzuschulenden Kinder verschafft. Das Gesamte Leistungsspektrum ist vertreten, von “weit unterdurchschnittlich” bis “weit überdurchschnittlich”.
Es gibt Studien (Linchevski und Kutscher 1998), die darauf hinweisen, dass eine heterogene Klassenzusammensetzung (leistungsstärkere und leistungsschwächere Kinder in einer Klasse) für die akademische Entwicklung der Kinder förderlich sein könnte, insbesondere für leistungsschwächere Kinder. Daher streben wir eine möglichst leistungsheterogene Klassenzusammensetzung an.
Mit der Programmiersprache R haben wir einen Algorithmus implementiert, um eine möglichst leistungsheterogene Klassenzusammensetzung zu erreichen. Dieser Algorithmus stellt sicher, dass das leistungsstärkste und das leistungsschwächste Kind in einer Klasse sind. Da die Kinder im Datensatz gemäß ihrer Leistung sortiert sind, befinden sich die leistungsstärkeren Kinder in der oberen Hälfte des Datensatzes und die leistungsschwächeren Kinder in der unteren Hälfte des Datensatzes. Das oberste (leistungsstärkste) und das unterste (leistungsschwächste) Kind im Datensatz werden einer Klasse zu geordnet. Dieser Prozess der Zuordnung (von oben und unten) wird stetig wiederholt, bis alle Kinder zugeordnet sind. Die Zuordnung (von oben und unten) erfolgt im Wechsel für die Klassen A, B und C.
Zuordnung von oben (leistungsstärkste Kinder): Klasse A, Klasse B, Klasse C, Klasse A, Klasse B, Klasse C, usw.
Zuordnung von unten (leistungsschwächste Kinder): Klasse A, Klasse B, Klasse C, Klasse A, Klasse B, Klasse C, usw.
Nachfolgend sehen wir den Algorithmus für die Klassenzuordnung, umgesetzt mit der Programmiersprache R, sowie die tabellarische Darstellung der Kinder mit entsprechender Klassenzuordnung.
R-Code aufklappen
# Algorithmus für die KlassenzuordnungKlasse <-c(rep(c("A", "B", "C"), length.out =ceiling(nrow(DATEN)/2)),rep(c("A", "B", "C"), length.out =ceiling((nrow(DATEN)/2)-1)) %>%rev() )
R-Code aufklappen
# Tabellarische Darstellung der Kinder mit entsprechender Klassenzuordnungcbind(DATEN, Klasse) %>%gt() %>%data_color(columns = Niveau,fn =function(x) {case_when( # Farbauswahl x =="weit überdurchschnittlich"~"#9B8BA8", # Purpur x =="überdurchschnittlich"~"#6B9AC4", # Blau x =="durchschnittlich"~"#A8C686", # Grün x =="unterdurchschnittlich"~"#E6B854", # Gelb x =="weit unterdurchschnittlich"~"#C85450"# Rot ) } ) %>%tab_header(title ="Testung vor Einschulung 2025/2026",subtitle ='Leistungen im Mathematik-Test "Mathes-0" in der KiTa bzw. Vorschule' )
Testung vor Einschulung 2025/2026
Leistungen im Mathematik-Test "Mathes-0" in der KiTa bzw. Vorschule
Pseudonym
Punkte (Rohwert)
Niveau
Klasse
Christo
33
weit überdurchschnittlich
A
Karien
32
weit überdurchschnittlich
B
Andre
31
überdurchschnittlich
C
Annelise
31
überdurchschnittlich
A
Frans
31
überdurchschnittlich
B
Thandi
31
überdurchschnittlich
C
Elizma
30
durchschnittlich
A
Pule
30
durchschnittlich
B
Temba
30
durchschnittlich
C
Adriaan
30
durchschnittlich
A
Leah
30
durchschnittlich
B
Simone
29
durchschnittlich
C
Xolani
29
durchschnittlich
A
Tshepo
29
durchschnittlich
B
Petra
29
durchschnittlich
C
Zola
29
durchschnittlich
A
Ruan
29
durchschnittlich
B
Liezl
29
durchschnittlich
C
Elma
29
durchschnittlich
A
Lerato
29
durchschnittlich
B
Coenie
29
durchschnittlich
C
Zinhle
29
durchschnittlich
A
Pieter
29
durchschnittlich
B
Kgothatso
29
durchschnittlich
C
Mandla
29
durchschnittlich
A
Thabo
29
durchschnittlich
B
Retha
29
durchschnittlich
C
Nokuthula
28
durchschnittlich
A
Tessa
28
durchschnittlich
B
Hanno
28
durchschnittlich
C
Vuyani
28
durchschnittlich
A
Palesa
28
durchschnittlich
B
Kobus
28
durchschnittlich
C
Iman
28
durchschnittlich
A
Bonolo
27
durchschnittlich
B
Herman
27
durchschnittlich
C
Mia
27
durchschnittlich
A
Anika
27
durchschnittlich
B
Lukas
27
durchschnittlich
C
Mariska
27
durchschnittlich
A
Bongi
27
durchschnittlich
B
Hendrik
27
durchschnittlich
C
Jana
27
durchschnittlich
A
Gert
27
durchschnittlich
B
Dawid
27
durchschnittlich
A
Sizwe
27
durchschnittlich
C
Olivia
27
durchschnittlich
B
Nadine
27
durchschnittlich
A
Yolandi
27
durchschnittlich
C
Noah
26
durchschnittlich
B
Leonie
26
durchschnittlich
A
Ricky
26
durchschnittlich
C
Kea
26
durchschnittlich
B
Sara
26
durchschnittlich
A
Brendan
26
durchschnittlich
C
Mpho
26
durchschnittlich
B
Elsa
26
durchschnittlich
A
Sarel
26
durchschnittlich
C
Riana
26
durchschnittlich
B
Siphamandla
26
durchschnittlich
A
Heinrich
25
durchschnittlich
C
Rocco
25
durchschnittlich
B
Mandla
25
durchschnittlich
A
Nandi
25
durchschnittlich
C
Sibusiso
25
durchschnittlich
B
Ruan
25
durchschnittlich
A
Karla
25
durchschnittlich
C
Pieter
25
durchschnittlich
B
Vuyani
25
durchschnittlich
A
Refilwe
25
durchschnittlich
C
Diego
25
durchschnittlich
B
Palesa
24
durchschnittlich
A
Temba
24
durchschnittlich
C
Marthinus
24
durchschnittlich
B
Nosipho
24
durchschnittlich
A
Thandi
24
durchschnittlich
C
Sarel
24
durchschnittlich
B
Petra
24
durchschnittlich
A
Hendrik
24
durchschnittlich
C
Elsa
24
durchschnittlich
B
Christo
24
durchschnittlich
A
Karien
23
unterdurchschnittlich
C
Leah
23
unterdurchschnittlich
B
Tshepo
23
unterdurchschnittlich
A
Amahle
23
unterdurchschnittlich
C
Coenie
23
unterdurchschnittlich
B
Sipho
20
weit unterdurchschnittlich
A
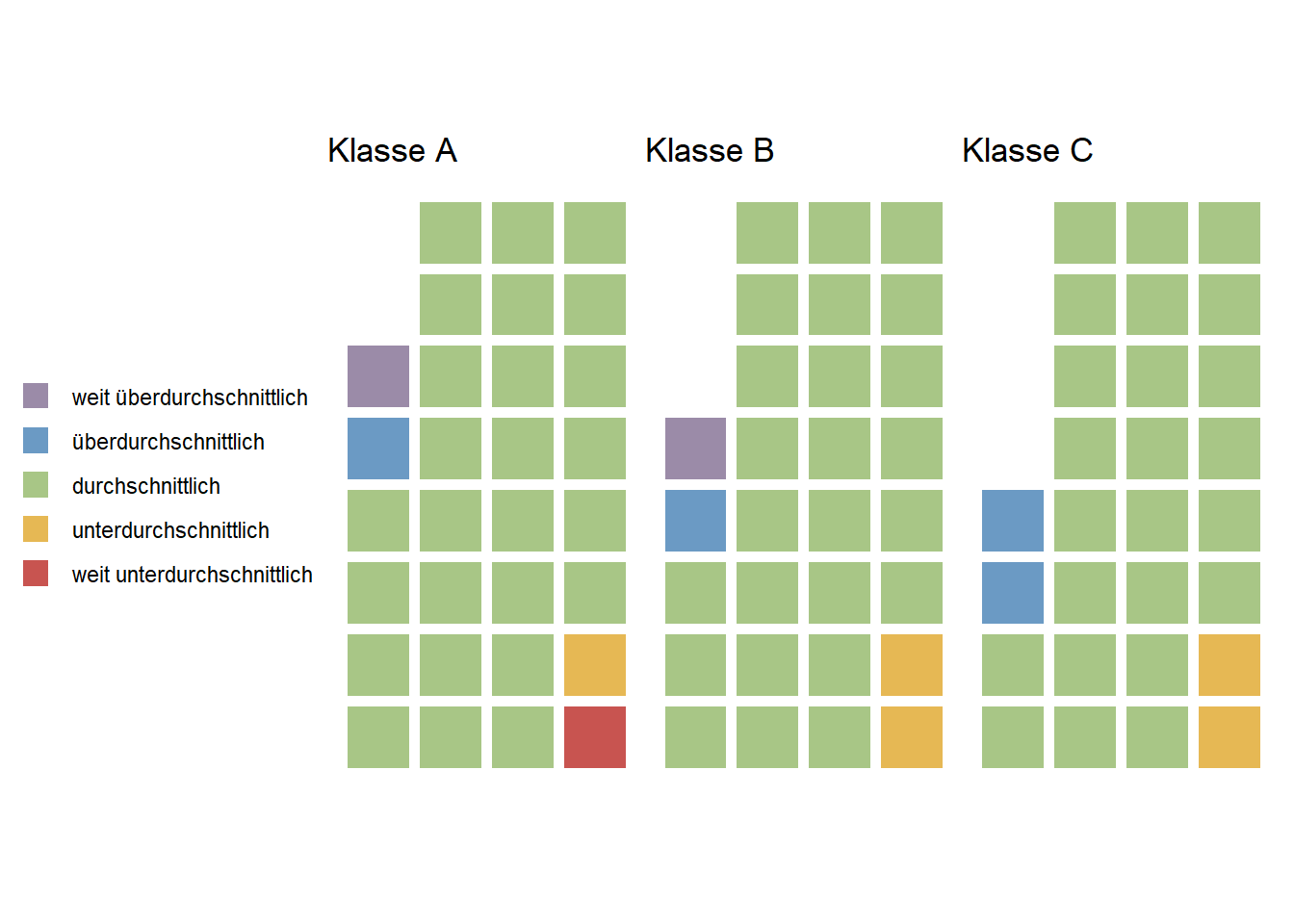
Entsprechende Waffel-Diagramme für die einzelnen Klassen veranschaulichen, dass wir tatsächlich eine leistungsheterogene Klassenzusammensetzung erreicht haben.
Der von uns implementierte Algorithmus der Klassenzuordnung stellt sicher, dass die leistungsstärksten und leistungsschwächsten Kinder tatsächlich in einer Klasse sind. Ein bloßes Abzählen bei der Zuordnung (Klasse A, Klasse B, Klasse C, Klasse A, Klasse B, Klasse C, usw.) würde dies nicht sicherstellen. Das leistungsschwächste Kind wäre dann nicht in einer Klasse mit dem leistungsstärksten Kind. Der von uns entwickelte Algorithmus hat sich für die Zusammensetzung leistungsheterogener Klassen daher als sehr nützlich erwiesen. Wir haben den Algorithmus der Klassenzuordnung daher frei zugänglich gemacht, damit auch andere Schulen den Algorithmus nutzen können. Dieses Teilen von Ressourcen, Tools und Techniken entspricht dem Leitgedanken der offenen Wissenschaftspraxis: Fortschritt und Weiterentwicklung durch gemeinsames Teilen und Kooperieren.
Linchevski, Liora, und Bilha Kutscher. 1998. „Tell Me with Whom You’re Learning, and I’ll Tell You How Much You’ve Learned: Mixed-Ability versus Same-Ability Grouping in Mathematics“. Journal for Research in Mathematics Education 29 (5): 533. https://doi.org/10.2307/749732.