3 Was ist R?
R (R Core Team 2021) ist eine herausragende, freie und zukunftsweisende Programmiersprache zur Datenverarbeitung und Datenanalyse. Mit dem vorangegangenen Beispiel haben wir einen ersten Einblick in die Verarbeitung, Analyse und Visualisierung von sozialen Netzwerkdaten mit R erhalten. An dieser Stelle kann aber keine umfassende Einführung in das Statistikprogramm R erfolgen. Hierfür konsultieren Sie bitte das hervorragende Buch “R kompakt - Der schnelle Einstieg in die Datenanalyse” (Wollschläger 2021). Dort erfahren Sie alle Grundlagen zur Installation und Ausführung von R sowie zur Datenverarbeitung, Datenanalyse und Datenvisualisierung mit R. In diesem Kapitel erfolgt dennoch ein kurze sowie exemplarische Einführung in die wichtigsten Grundlagen von R. Für die praktische Arbeit mit R wird die Arbeitsumgebung RStudio (RStudio Team 2020) empfohlen.
3.1 Statistische Datenanalyse
Wenn wir die Sozialbeziehungen in sozialen Gruppen betrachten wollen, so erscheint eine statistische Beschreibung der sozialen Gruppe sinnvoll. Wir sind z.B. interessiert an den persönlichen Merkmalen und Eigenschaften der Schüler*innen in einer Klasse (z.B. Alter, Geschlecht, Verhaltensweisen, usw.). Informationen dieser Art werden in Datensätzen gespeichert.
Name | Alter | Geschlecht | Introvertiertes Verhalten (IV) |
Susi | 6 | 0 | 4 |
Eda | 6 | 0 | 1 |
Ella | 7 | 0 | 4 |
Lena | 6 | 0 | 3 |
Max | 5 | 1 | 2 |
Ali | 6 | 1 | 1 |
Til | 6 | 1 | 2 |
Mit R erstellen wir die 4 Variablen (name, alter, geschlecht, IV) als Objekte mit dem Zuweisungspfeil <-. Die Werte der jeweiligen Variablen werden dabei mit der Funktion c() zusammengefasst (combine values into a vector).
name <- c("Susi", "Eda", "Ella", "Lena", "Max", "Ali", "Til")
alter <- c(6, 6, 7, 6, 5, 6, 6)
geschlecht <- c(0, 0, 0, 0, 1, 1, 1)
IV <- c(4, 1, 4, 3, 2, 1, 2)Mit R kann man sich stets alle Objekte anschauen, indem man diese einfach “aufruft”. Wir betrachten die Variable introvertiertes Verhalten (IV).
IV # Variable aufrufen und anzeigen## [1] 4 1 4 3 2 1 2Die 4 Variablen werden nun in einem Datensatz zusammengefasst. Dabei werden die Variablen an die Funktion data.frame() übergeben. Wir erstellen mit der Funktion data.frame() ein neues Objekt (den Beispieldatensatz). Der Beispieldatensatz wird anschließend aufgerufen und angezeigt.
beispieldatensatz <- data.frame(name, alter, geschlecht, IV)
beispieldatensatz # Beispieldatensatz aufrufen und anzeigen## name alter geschlecht IV
## 1 Susi 6 0 4
## 2 Eda 6 0 1
## 3 Ella 7 0 4
## 4 Lena 6 0 3
## 5 Max 5 1 2
## 6 Ali 6 1 1
## 7 Til 6 1 2Nun möchten wir die Daten analysieren. Wir betrachten das introvertierte Verhalten (IV) der Kinder. Mit beispieldatensatz$IV können wir die entsprechende Variable des Beispieldatensatzes aufrufen. Wir berechnen den Mittelwert mit der Funktion mean() und den getrimmten Mittelwert indem wir zusätzlich das Argument trim = 0.2 festlegen. Die Variable beispieldatensatz$IV wird dabei an die Funktion mean() übergeben.
beispieldatensatz$IV # Variable des Beispieldatensatzes aufrufen und anzeigen## [1] 4 1 4 3 2 1 2mean(beispieldatensatz$IV) # Mittelwert## [1] 2.428571mean(beispieldatensatz$IV, trim = 0.2) # Getrimmter Mittelwert## [1] 2.43.2 Datenimport
In den allermeisten Fällen sind die zu analysierenden Daten als Excel- oder CSV-Dateien auf der Festplatte oder in einer Cloud gespeichert. Für die Analysen mit R müssen diese Daten zunächst eingelesen werden (Datenimport).
Hier finden Sie den bekannten Beispieldatensatz als CSV-Datei (Link zur CSV-Datei1) und als Excel-Datei (Link zur Excel-Datei2). Speichern Sie die beiden Dateien auf Ihrer Festplatte, z.B. auf dem Desktop.
Mit R gibt es viele Wege um Daten einzulesen. Hier nur ein Beispiel für die CSV-Datei. Sie müssen den Dateipfad (Speicherort und Dateinamen mit Dateiendung) an die Funktion read.csv2() übergeben.
daten <- read.csv2("C:/Users/pawel/Desktop/daten.csv")Das Einlesen einer Excel-Datei gelingt mit der Funktion read_excel(). Zuvor muss allerdings das entsprechende R-Zusatzpaket readxl (Excel) (Wickham und Bryan 2019) installiert und geladen werden.
install.packages("readxl") # R-Zusatzpaket readxl (Excel) installieren
library(readxl) # R-Zusatzpaket readxl (Excel) laden
daten <- read_excel("C:/Users/pawel/Desktop/daten.xlsx")Wir können auch auf die Angabe des Dateipfades verzichten und stattdessen mit der Funktion file.choose() das Dateiverzeichnis nach der entsprechenden CSV- oder Excel-Datei durchsuchen.
daten <- read_excel(file.choose())Die Daten können aber auch direkt aus dem Internet eingelesen werden. Hierfür benötigen wir lediglich den Link zur Datei (dies kann auch ein geteilter Link zu einer Datei in einer Cloud sein).
daten <- read.csv2("https://figshare.com/ndownloader/files/31108225")In allen Fällen war das einlesen des Beispieldatensatzes erfolgreich und wir können den Datensatz aufrufen.
daten## name alter geschlecht IV
## 1 Susi 6 0 4
## 2 Eda 6 0 1
## 3 Ella 7 0 4
## 4 Lena 6 0 3
## 5 Max 5 1 2
## 6 Ali 6 1 1
## 7 Til 6 1 23.3 Datenvisualisierung
R eignet sich vorzüglich zur Visualisierung von Daten. Wir erstellen ein Histogramm der Variable IV.
hist(daten$IV)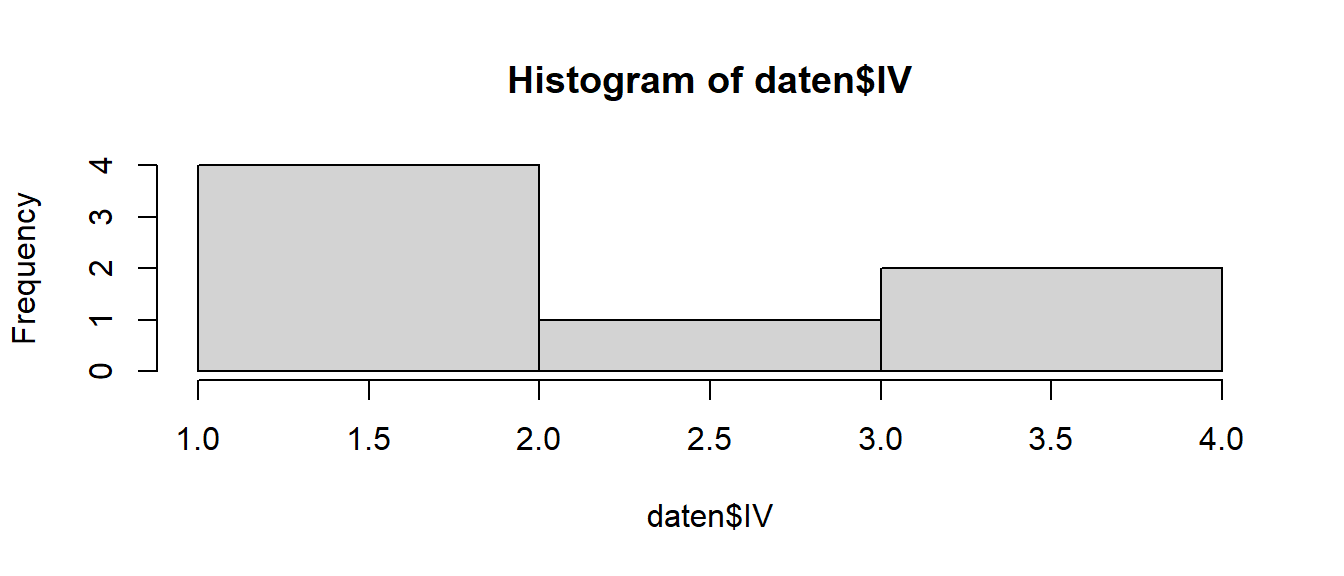
Figure 3.1: Histogramm
Mittlerweile sind die Grafikbefehle des Zusatzpaketes ggplot2 (Wickham 2016) der Standard bei der Erstellung von Grafiken mit R. Das Zusatzpaket ggplot2 ist in der Paketsammlung tidyverse enthalten. tidyverse (Wickham u. a. 2019) ist wiederum eine Zusammenstellung vieler extrem nützlicher Zusatzpakete (z.B. Werkzeuge fürs Datenmanagement).
install.packages("tidyverse")
library(tidyverse)Wir erstellen ein Histogramm mit den Grafikbefehlen des Zusatzpaketes ggplot2.
ggplot(data = daten, mapping = aes(IV)) + geom_histogram()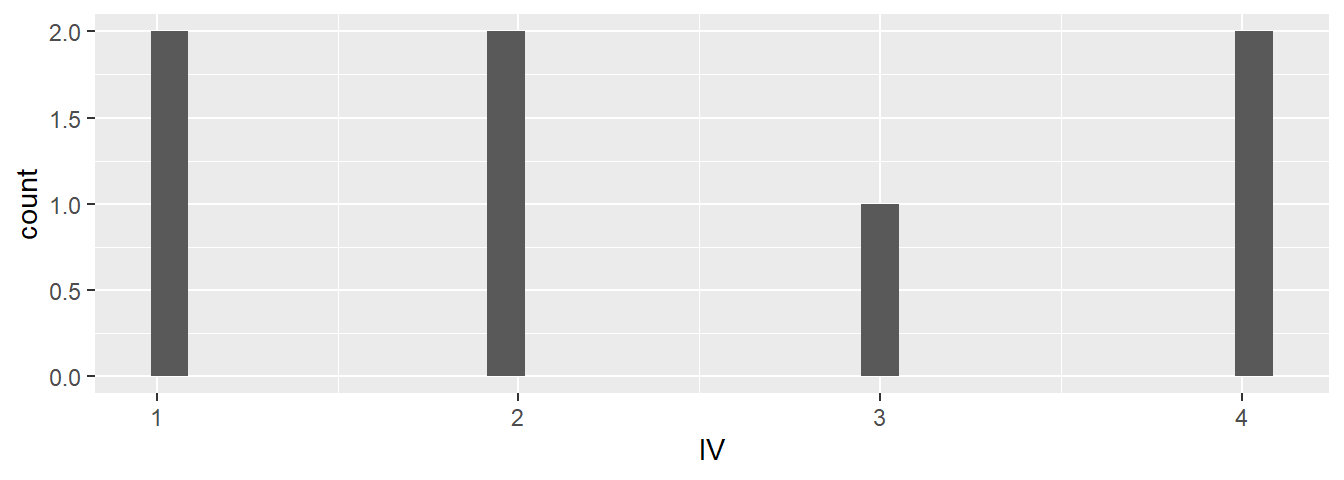
Figure 3.2: Histogramm mit ggplot2
3.4 Der Pipe-Operator |> bzw. %>%
R-Funktionen können ineinander geschachtelt werden. Dies ist z.B. notwendig bei der Visualisierung einer Häufigkeitstabelle. Zunächst erstellen wir die benötigte Häufigkeitstabelle der Variable alter.
table(daten$alter)##
## 5 6 7
## 1 5 1Zur Visualisierung der Häufigkeitstabelle wird table(daten$alter) an den Befehl pie() (Kreisdiagramm/Tortendiagramm) übergeben.
pie(table(daten$alter), main = "Alter in Jahren")Diese Schachtelung von Befehlen (table() innerhalb von pie()) ist unübersichtlich. Eine objektorientierte Programmierung ist übersichtlicher (auch dies führt zur erfolgreichen Visualiserung).
table_alter <- table(daten$alter)
pie(table_alter, main = "Alter in Jahren")Noch übersichtlicher ist die “Weitergabe” der Häufigkeitstabelle an den Grafik-Befehl mittels Pipe-Operator |> bzw. %>% (auch dies führt zur erfolgreichen Visualiserung). Dabei ist es in den meisten Fällen unerheblich ob |> oder %>% genutzt wird. %>% entstammt aus der Paketsammlung tidyverse (Wickham u. a. 2019) und bietet einige Vorteile gegenüber |>. Insgesamt ist der Pipe-Operator (egal ob |> oder %>%) ein sehr nützliches Werkzeug.
table(daten$alter) |> pie(main = "Alter in Jahren")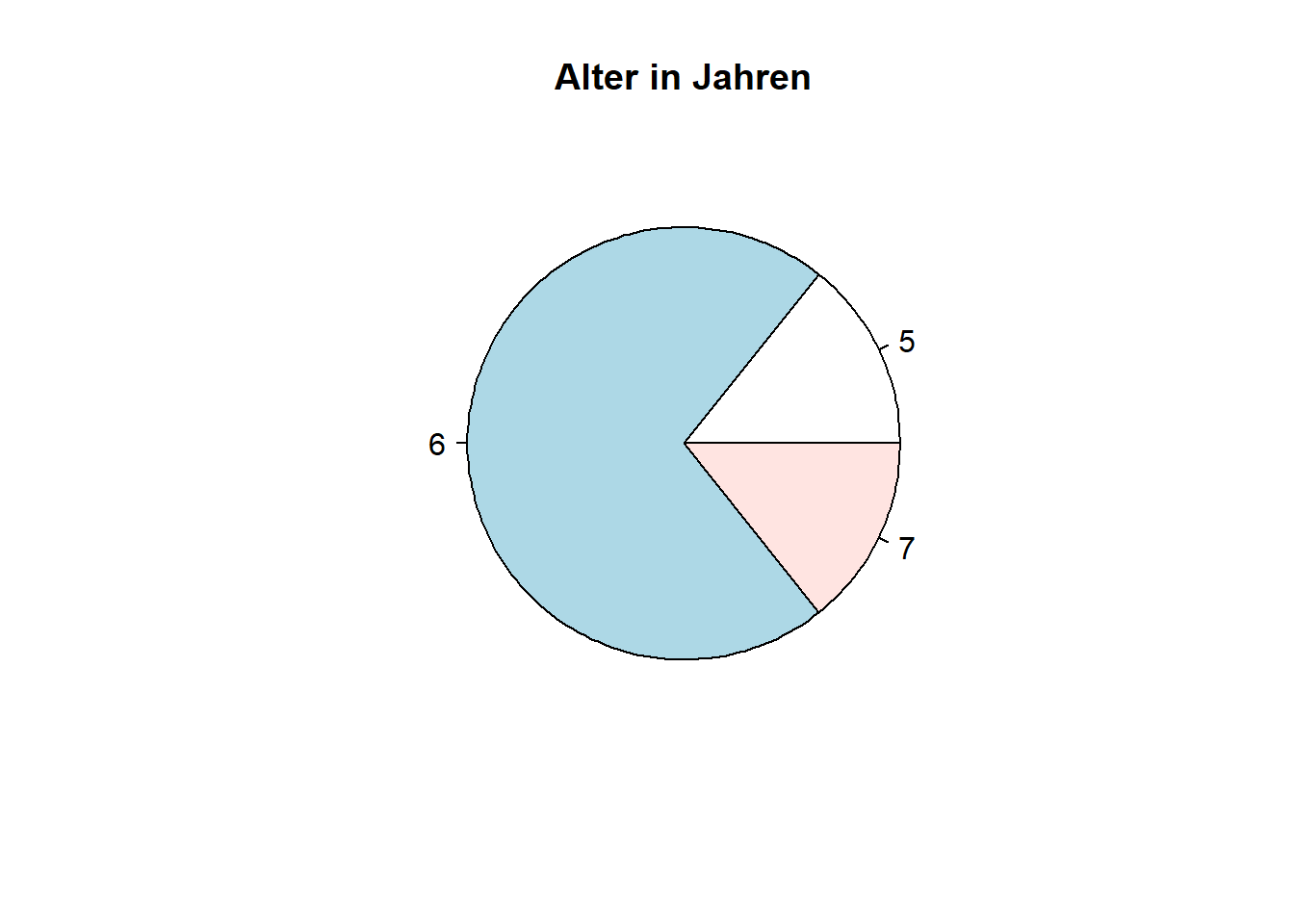
Figure 3.3: Kreisdiagramm